Que estudiaremos?
- Exploremos que estaciones se comportan de forma similar
- Con la facilidad que R y highcharter nos ofrecen (espero!)
Data
Se tienen el ingreso promedio de personas cada media hora
## # A tibble: 3,737 × 3
## paraderosubida mediahora subidas_laboral_promedio
## <chr> <dbl> <dbl>
## 1 Alcantara 19800000 2.6
## 2 Alcantara 21600000 13.2
## 3 Alcantara 23400000 53.4
## 4 Alcantara 25200000 184.8
## 5 Alcantara 27000000 364.0
## 6 Alcantara 28800000 546.2
## 7 Alcantara 30600000 478.6
## 8 Alcantara 32400000 359.0
## 9 Alcantara 34200000 275.4
## 10 Alcantara 36000000 229.6
## # ... with 3,727 more rows
Correlaciones
dcor <- pairwise_cor(data, paraderosubida, mediahora, subidas_laboral_promedio,
upper = FALSE)
## # A tibble: 5,050 × 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 Laguna Sur Las Parcelas 0.9979128
## 2 Plaza Maipu San Pablo 0.9962208
## 3 Laguna Sur Plaza Maipu 0.9960967
## 4 Del Sol Las Parcelas 0.9960689
## 5 La Granja San Ramon 0.9960405
## 6 Las Parcelas Plaza Maipu 0.9955500
## 7 Las Parcelas Protectora De La Infancia 0.9953642
## 8 Plaza Maipu Protectora De La Infancia 0.9953066
## 9 El Parron Lo Ovalle 0.9951739
## 10 Neptuno San Pablo 0.9951252
## # ... with 5,040 more rows
dcorf <- seleccionamos_las_mas_grandes(dcor)
Network
g <- graph_from_data_frame(dcorf, directed = FALSE)
g <- maquillamos_red(g)
hchart(g)
Autoencoder
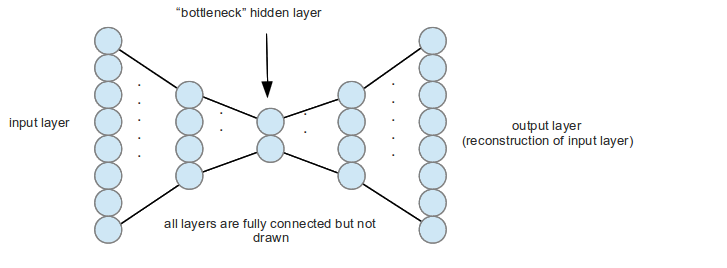
Modelo/Técnica usada para reducir la dimensionalidad de la información: resumir.
Preparando Datos
Los datos los necesitamos en formato ancho para así tener una fila(observación) por estación.
data2 <- spread(data, mediahora, subidas_laboral_promedio)
data2
## # A tibble: 101 × 7
## paraderosubida m19800 m21600 m23400 m25200 m27000 m28800
## * <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Alcantara 2.6 13.2 53.4 184.8 364.0 546.2
## 2 Baquedano 88.0 132.6 234.6 493.4 721.4 782.2
## 3 Barrancas 37.0 195.4 406.4 736.8 799.6 660.4
## 4 Bellas Artes 6.6 37.0 92.2 177.6 282.2 295.2
## 5 Bellavista De La Florida 157.6 297.8 565.8 1113.6 1162.8 1303.4
## 6 Blanqueado 35.8 199.6 411.4 646.4 736.8 620.6
## 7 Cal Y Canto 103.0 575.2 1281.0 2309.0 2640.2 2484.0
## 8 Camino Agricola 38.2 113.2 281.6 530.6 606.0 572.6
## 9 Carlos Valdovinos 46.2 113.0 210.4 342.4 431.0 407.4
## 10 Cementerios 20.8 78.4 167.6 249.8 255.0 223.0
## # ... with 91 more rows
Al aplicar el modelo
Luego de obtener la capa intermedia:
## # A tibble: 101 × 3
## x y paraderosubida
## <dbl> <dbl> <chr>
## 1 0.6394547 -0.52724736 Alcantara
## 2 0.2071398 0.09132581 Baquedano
## 3 0.6498987 -0.71001571 Barrancas
## 4 0.6835166 -0.49108763 Bellas Artes
## 5 0.2678762 -0.57183469 Bellavista De La Florida
## 6 0.6582246 -0.72496392 Blanqueado
## 7 -0.4430200 -0.14534241 Cal Y Canto
## 8 0.5895484 -0.47734199 Camino Agricola
## 9 0.6915719 -0.66536221 Carlos Valdovinos
## 10 0.7397002 -0.70456962 Cementerios
## # ... with 91 more rows
Observar la representación gráfica
hchart(dautoenc, "point", hcaes(x = x, y = y), name = "Estaciones")
Qué nos dicen estos grupos?
Alguien dijo Geográficamente?



